
Classification is a process related to categorization, the process in which ideas and objects are recognized, differentiated and understood. Classification task is the process of predicting a class when multiple data points are given. This classifier uses a training data to understand how the variables that are given as input, identify with a specific class. Out of multiple classification algorithms, Naive Bayes is the one I am using for this project as it gives better performance than others.
In this project, I implemented a text classifier to classify movie genres according to the input given by the user. The dataset consists of many movies with multiple genres so it is a multi-class classification. Text classification helps identify the classes based on the multiple columns data(Overview, etc.).
Naive Bayes Classifier
The Naive Bayesian classifier is based on Bayes’ theorem with the independence assumptions between predictors. A Naive Bayesian model is easy to build, with no complicated iterative parameter estimation which makes it particularly useful for very large datasets. The classification is carried out by calculating the probability of each given class, and displaying the classes with the highest probabilities as the output.
Bayes theorem provides a way of calculating the posterior probability, P(c|x), from P(c), P(x), and P(x|c). Naive Bayes classifier assume that the effect of the value of a predictor (x) on a given class (c) is independent of the values of other predictors. This assumption is called class conditional independence.

- P(c|x) is the posterior probability of class (target) given predictor (attribute).
- P(c) is the prior probability of class.
- P(x|c) is the likelihood which is the probability of predictor given class.
- P(x) is the prior probability of predictor.
t1, t2, t3, … = Terms in data
Formula Used:
Probability(Genre|[Term1, Term2, Term3, …, Termn]) = Probability(Genre) * Probability(Term1|Genre) * Probability(Term2|Genre) * Probability(Term3|Genre) * … * Probability(Termn|Genre)
Procedure:
In the given movielens dataset that has been downloaded from Kaggle, the column that has the genres of the movies is going to be predicted with the help of a given overview or plot of the movies.
For the evaluation step, the data can be divided into training data, testing data. In the given dataset, the training and testing data is divided into 80% and 20% respectively. The dataset has 45,467 records. So, it is divided as 36,374 records for training data and 9,093 records for test data.
Now using Naive bayes algorithm,
- we find out the prior probability P(c) and P(x)[Formula given above]. Number of records in class c divided by total number of records.
- Then we find out the conditional probability, by calculating the frequency of a term in a record, of class x or c. P(x|c) and P(c|x).
After this whenever their is input for the classification, we do the preprocessing and filtering of the collection using stemming, lemmatization and removal of stopwords.
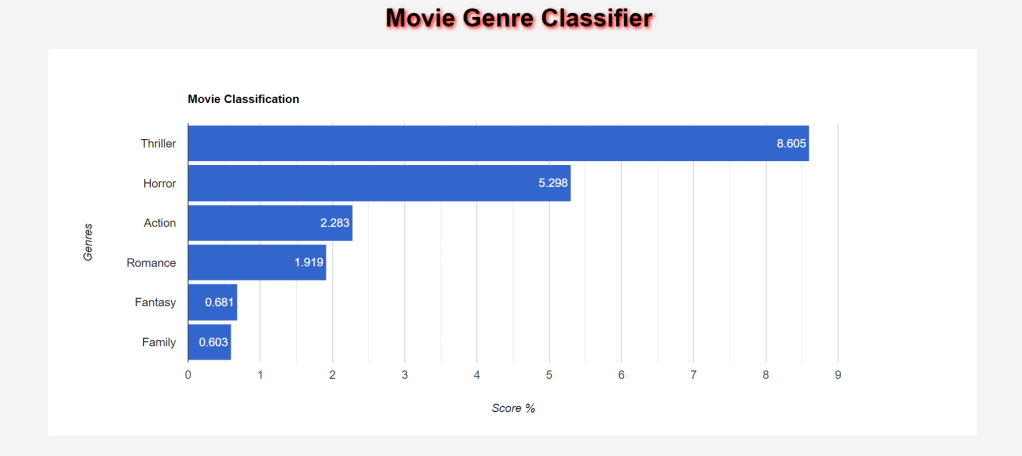
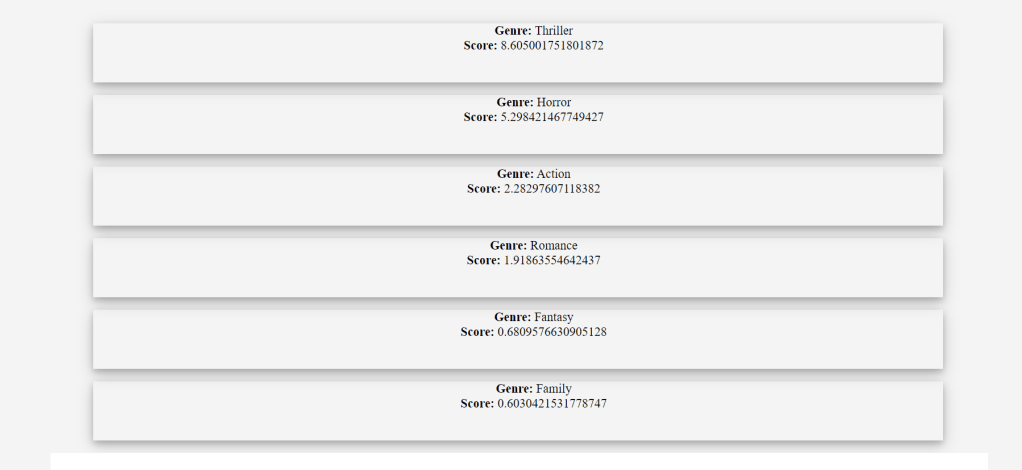
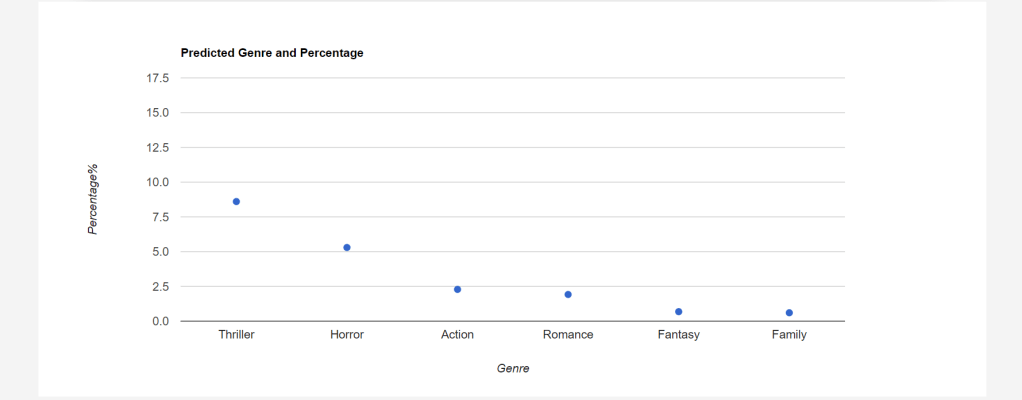
After evaluation, a score will be given to each class and using this score the genre is predicted according to the input query.
Now, to calculate the Accuracy, we send the movie overview(plot) of the test data to the input of the training data and then compare the predicted and actual genres of that movie overview.
My Contributions:
- The model was working on the whole dataset. So, splitting the dataset into test data and train data was done by me. Along with training it to get results along with the accuracy.
- The classification time to predict the genre was taking alot of time due to calculating again and again, so I used .pkl file to store probabilities to save time.
- Since the model was not trained, there was no evaluation metrics. I calculated the accuracy of the model as my evaluation metrics.
- Display the data in the charts to show the result in better orderly manner and also so that the user can see the predictions clearly. And how much is the percentage of each Genre.
- The classifier was built from scratch to implement the Naive bayes classification, without using any library.
# Code to save probabilities in pickle files
def get_results(query):
global prior_probability, post_probability
initialize()
if os.path.isfile("classifierPicklePrior.pkl"):
prior_probability = pickle.load(open('classifierPicklePrior.pkl', 'rb'))
post_probability = pickle.load(open('classifierPicklePost.pkl', 'rb'))
else:
(prior_probability, post_probability) = build_and_save()
return eval_result(query)Experiments:
- I also implemented the SVM(Support Vector Machine) using the Skearn library because of that I was able to changes in the Accuracy, it went up to 58.39% using that.
- For the Naive Bayes classifier, I used multiple ratios for the training and testing data split like 70:30, 80:20, 90:10 etc. respectively and I was able to see the difference in the accuracy of percentage between 37%-45%. Initially, I was comparing the results from one of the genres of the overview input, but when I tried it for comparision with the multiple genres I got the accuracy of 57.44%.
# Code to calculate Probabilities from the tokens
for (genre, token) in token_genre_count_map:
post_probability[(genre, token)] = token_genre_count_map[(genre, token)] / token_count
prior_probability = {x: genre_count_map[x]/row_count for x in genre_count_map}
save(prior_probability, post_probability)
return (prior_probability, post_probability)#Code to show final results
def eval_result(query):
processed_query = pre_processing(query)
sum=0
genre_score = {}
perc = []
notrequiredlist={'Vision View Entertainment', 'Aniplex', 'GoHands', 'BROSTA TV', 'Rogue State','Carousel Productions', 'Odyssey Media', 'Sentai Filmworks', 'Pulser Productions', 'Mardock Scramble Production Committee', 'Telescene Film Group Productions', 'The Cartel' }
for genre in prior_probability.keys():
if genre in notrequiredlist:
continue
score = prior_probability[genre]
for token in processed_query:
if (genre, token) in post_probability.keys():
score = score * post_probability[(genre, token)]
genre_score[genre] = score
sorted_score_map = sorted(genre_score.items(), key=operator.itemgetter(1), reverse=True)
# sorted_score_map = sorted_score_map*10000000
# print(sorted_score_map)
for i in sorted_score_map:
sum += i[1]
for i in range(len(sorted_score_map)):
perc.append([sorted_score_map[i][0], sorted_score_map[i][1], (sorted_score_map[i][1] / sum) * 100])
return perc, sorted_score_map# Code to check Accuracy
def testAccuracy(test_data):
num_correct_predictions = 0
print(type(test_data), test_data)
for index in list(test_data.index):
y_result = test_data.at[index, 'genres']
query = test_data.at[index, 'overview']
y_predict = get_results(query)[:5]
for genre in y_predict:
if y_result == genre[0]:
num_correct_predictions+=1
accuracy = num_correct_predictions/len(test_data)
return accuracyChallenges Faced:
- The accuracy got is 39.6% for a split estimation of 0.3 The reason behind why the accuracy is so low is a direct result of the blemish in the language that has been utilized in the dataset, and furthermore, as a wide assortment of words have been repeated in a different classes. So, when I changed the split ratio to 80:20, with removing some of the unwanted genres I got the accuracy of 42.63%.
- The classification time to predict the genre was taking alot of time due to calculating again and again, so I used .pkl file to store probabilities to save time.
- Due to lack of Machine Learning Knowledge, the conceptual understanding of Machine Learning Classifier was not clear and it took me lot of time on that along with the issues of training a model. It took me alot of time to fully implement the concept.
References:
- https://www.saedsayad.com/naive_bayesian.htm
- https://github.com/napandya/Movie-Recommender/blob/master/query_classifier.py
- https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c
